%%{init: {
"theme": "base",
"themeVariables": {
"primaryColor": "#dbeafe",
"primaryBorderColor": "#2563eb",
"primaryTextColor": "#1e3a5f",
"edgeLabelBackground": "#f8fafc",
"lineColor": "#64748b",
"fontFamily": "Georgia, serif",
"fontSize": "20px"
}
}}%%
flowchart LR
D((" Data ")) -- Inference --> P((" P(x) "))
P -- Sampling --> D
style D fill:#dbeafe,stroke:#2563eb,stroke-width:3px,color:#1e3a5f,font-weight:bold
style P fill:#fee2e2,stroke:#dc2626,stroke-width:3px,color:#1e3a5f,font-weight:bold
linkStyle 0 stroke:#64748b,stroke-width:4px
linkStyle 1 stroke:#64748b,stroke-width:4px
Lecture 1: Associatie en interventie
1 Overzicht
In deze les geven we een inleiding in de (statistische) fundamenten waarop moderne data-analyse gebouwd is. Kernbegrippen zoals kansverdeling, voorwaardelijke kans en marginale kans komen aan bod, met bijzondere aandacht voor hoog-dimensionale kansruimten.
Daarna staan we uitgebreid stil bij de “ladder van causaliteit” en de beperkingen van zuiver observationele studies. Dit onderscheid — tussen het beschrijven van patronen en het begrijpen van oorzaken — is een van de meer onderschatte inzichten in de moderne data-analyse, met directe implicaties voor optimaliseren van bedrijfsprocessen.
2 Data en kansen
2.1 Data als grondstof voor inzicht
Data is de grondstof van elk beslissingsproces dat op kwantitatieve manier verliezen wil wegwerken en zaken zoals procesvariatie en afkeur wil onder controle brengen. In een industriële omgeving zijn de bronnen divers: van sensorwaarden en kwaliteitsmetingen tot financiële rapporten en onderhoudslogboeken.
Typische databronnen in de industrie
- Procesbeheersing, zoals temperatuurverliezen bij staalproductie;
- Betrouwbaarheid, zoals de Mean Time Between Failures (MTBF): de gemiddelde tijd tussen twee opeenvolgende pannes;
- Financiële resultaten: omzet, marge, kosten, …
De variëteit en omvang van deze data stelt ons voor een uitdaging: hoe gaan we er rigoureus mee om? Het antwoord ligt in de wiskundige taal van de kanstheorie.
Statistisch denken
Kanstheorie is het leidend paradigma om met onzekerheid om te gaan maar daarom niet het enige paradigma. Er bestaat bijvoorbeeld ook de vage wiskunde (fuzzy mathematics).
2.2 Kanstheorie
Kanstheorie werkt met kansverdelingen: wiskundige functies die aangeven hoe de data zich gedraagt.
Data en kansverdelingen: twee zijden van dezelfde medaille
Data en kansverdelingen zijn zeer nauw verwant. Gegeven de kansverdeling kunnen we eruit samplen om data te genereren; andersom kunnen we een kansverdeling infereren vanuit waargenomen data. Het is goed om over de twee te denken als twee zijden van een medaille: twee “schaduwen” van eenzelfde abstract concept.
Note
In de praktijk observeren we slechts een eindige hoeveelheid data. De echte onderliggende kansverdeling kan daar niet volledig mee beschreven worden. Een deel van de moeilijkheid zit er dus in om vanuit die beperkte steekproef toch zinvolle uitspraken te doen over de volledige verdeling.
Kansverdelingen
Zoals eerder gezien in de cursus kan een kansverdeling kan op twee manieren worden gevisualiseerd met functies die aangeven hoe plausibel het is om data aan te treffen in een bepaald gebied:
- De probability density function (pdf): beschrijft hoe waarschijnlijk elke mogelijke uitkomst is. De pdf \(f(x) = P(X = x)\) geeft de kans op een bepaalde waarde \(x\).
- De cumulative distribution function (cdf): geeft de kans dat een willekeurige waarde kleiner of gelijk is aan een gegeven drempel. De cdf \(F(x) = P(X \leq x)\) geeft de kans dat een willekeurig getal uit de verdeling kleiner of gelijk is aan \(x\):
De twee functies zijn nauw verwant: de cdf is de integraal van de pdf, en de pdf is de afgeleide van de cdf.
\[F(x) = \int_{-\infty}^{x} f(t)\,dt\]
Te onthouden
- pdf: de vorm van de verdeling — hoe waarschijnlijk is elke uitkomst?
- cdf: de gecumuleerde kans — hoe groot is de kans op een waarde ≤ x?
Note
De uitdrukking \(f(x) = P(X = x)\) heeft eigenlijk geen fysische betekenis voor continue variabelen, vermits de kans op een exact waarde is steeds nul. We noemen \(f\) We spreken dan van kansdichtheid. De fysisch zinvolle grootheden zijn bepaalde integralen van de kansdichtheid:
\[P(x_1 \leq X \leq x_2) = \int_{x_1}^{x_2} f(x)\,dx = F(x_2) - F(x_1)\]
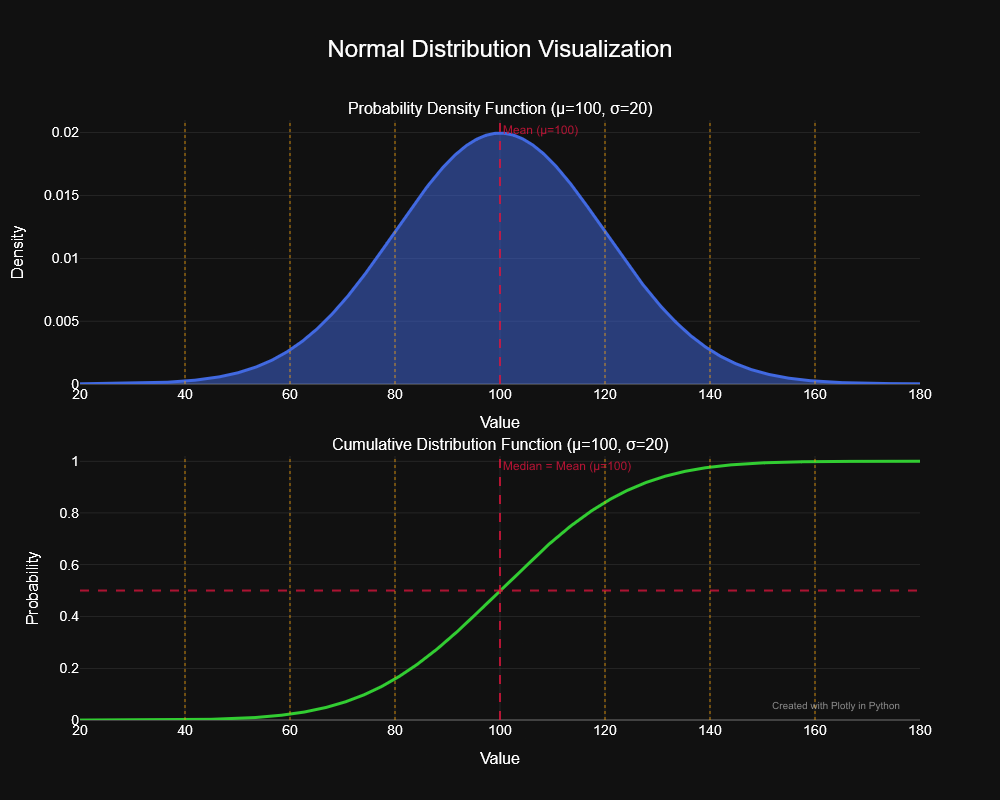
De normale verdeling
De meest bekende kansverdeling is de normale verdeling (ook wel Gaussissche verdeling). Ze wordt volledig beschreven door twee parameters:
- \(\mu\): het gemiddelde (bepaalt waar de piek zich bevindt)
- \(\sigma\): de standaarddeviatie (bepaalt de breedte van de curve)
Niet alles is normaal
Hoewel de normale verdeling alomtegenwoordig is, ook in deze opleiding, volgen lang niet alle fenomenen in de praktijk een normale verdeling.
Denk aan:
- Wachttijden (exponentieel verdeeld)
- Afkeurcijfers tussen 0% en 100% (bv. beta-verdeling)
- Data van tellingen zoals het aantal klachten of aankomsten per tijdseenheid (Poisson-verdeling)
2.3 Sampling en inference
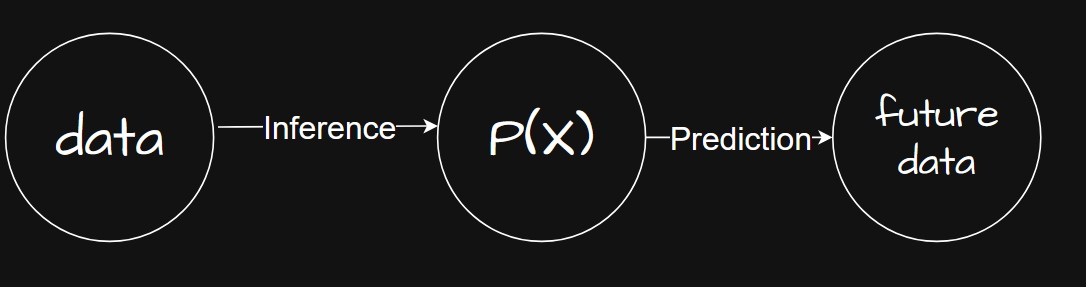
De relatie tussen data en kansverdelingen wordt beschreven door twee complementaire processen:
- Sampling: data genereren vanuit een kansverdeling — dit doet de natuur voor ons.
- Inference: de onderliggende kansverdeling begrijpen op basis van beschikbare data — dit is de taak van statistiek en data science.
Praktijkvoorbeeld: klantenstromen aan de kassa
Stel dat een winkel bijhoudt hoeveel klanten per minuut aan de kassa arriveren. Na data-verzameling stellen we vast dat de aankomsten goed beschreven worden door een Poisson-verdeling met parameter \(\lambda = 2\,959\). We hebben de statistische verdeling geïnfereerd uit de data.
2.4 Inference als voorspelling
Het doel van inference is niet louter het beschrijven van het verleden, maar het onderbouwen van uitspraken over de toekomst.
“Life can only be understood backwards, but it must be lived forwards.” — Søren Kierkegaard
Typische toepassingen in een bedrijfscontext:
- Processen optimaliseren om verliezen te minimaliseren
- Onderbouwen van grote investeringsbeslissingen
- Kost-baat analyses maken van verschillende productleveranciers
Voorbeeld
Op basis van de geïnfereerde Poisson-verdeling voor klantenstromen (\(\lambda = 2.959\)) kunnen we uitspraken doen zoals:
“Er is minder dan 2% kans dat er meer dan 7 klanten per minuut arriveren.”
3 Associatie
Nu we het verband tussen data en kansverdelingen hebben opgefrist is het tijd om te kijken naar meerdimensionale datasets: we gaan wiskundig onderbouwen wat het betekent dat er verbanden aanwezig zijn in de data, en hoe we deze verbanden kunnen gebruiken om toekomstige observaties te voorspellen.
3.1 Data in meer dimensies
Hiervoor beperkten we ons tot één variabele. In de meeste praktische toepassingen heeft elke observatie meerdere kenmerken (features) tegelijk:
- De volledige aankoopgeschiedenis van een klant
- Duizenden pixelwaarden per afbeelding
- Bij het continugieten van staal: gebruikte soort stopper en hoeveelheid afkeur
Het is precies de interactie tussen deze features die toelaat zinnige voorspellingen te doen over toekomstige observaties!
Kanstheorie is gelukkig ook toepasbaar in meerdere dimensies: we spreken dan van een gezamenlijke kansverdeling \(P(X_1, X_2, \ldots, X_n)\). Het is hierbij toegelaten dat sommige van de variabelen \(X_i\) discreet zijn en andere continu. We verkennen dit concept kort aan de hand van enkele voorbeelden.
Big data is in de eerste plaats veel dimensies
De voornaamste uitdaging bij big data is niet enkel het volume, maar ook de dimensionaliteit: het grote aantal variabelen dat tegelijk in beschouwing genomen moet worden.
De multivariate normale verdeling
De normale verdeling kan worden uitgebreid naar meerdere dimensies: de multivariate normale verdeling. In twee dimensies ziet dit eruit als een “heuvelvormig” landschap boven het vlak.
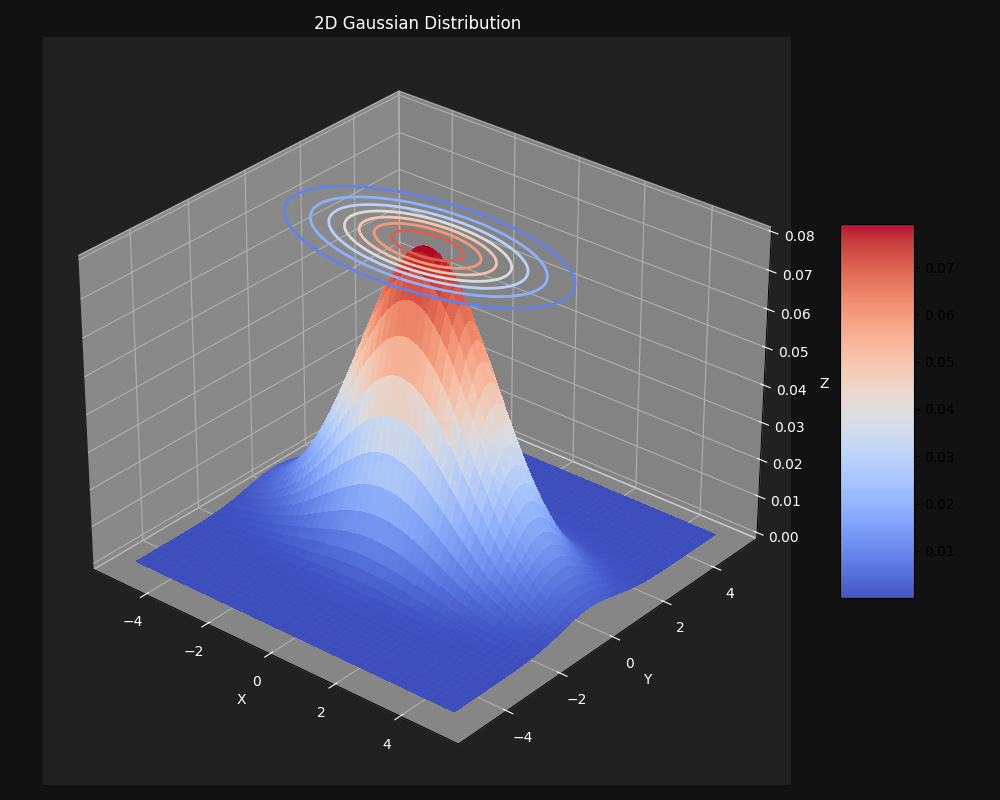
Wat in hogere dimensies? Volgend advies wordt toegeschreven aan Geoffrey Hinton, soms de Godfather of AI genoemd:
“To visualize 4 dimensions, visualize 3 and say ‘four’ very loudly. To visualize 14 dimensions, visualize 3 and say ‘fourteen’ even louder.”
Gewichten van mannen en vrouwen
Beschouw een dataset met twee variabelen: geslacht \(G\) (een discrete variabele) en massa \(M\) in kg (een continue variabele). We modelleren dit als een tweedimensionale gezamenlijke verdeling \(P(M, G)\).
Het ziet er nu een beetje raar uit omdat één as een discrete as is, maar het concept is hetzelfde:
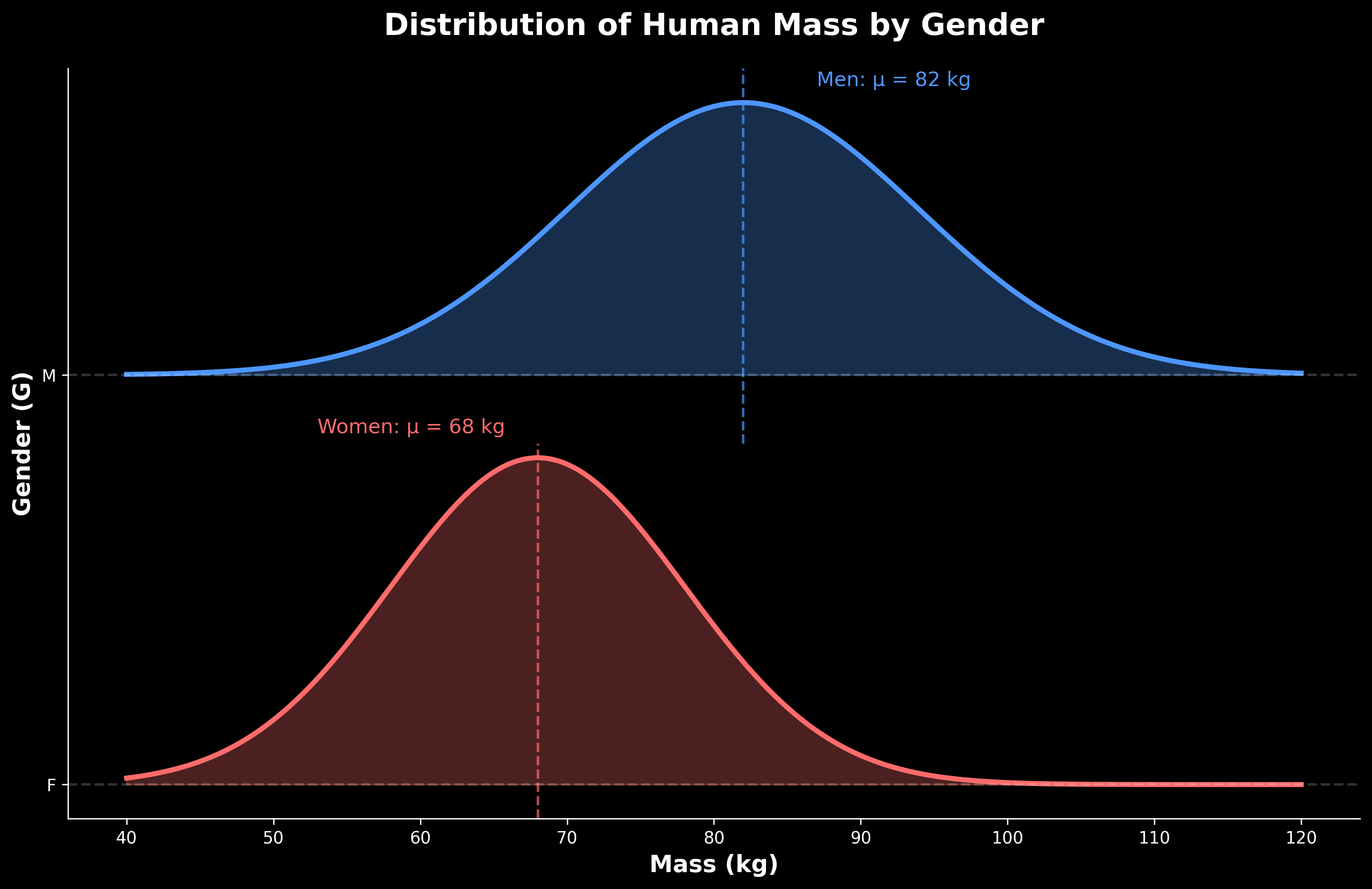
De waarde \(P(G = \text{man},\, M = 100)\) geeft de kansdichtheid voor een mannelijke observatie van 100 kg.
Meer voorbeelden
Productiekwaliteit:
\[P(L,\, B,\, S)\]
waarbij \(L\) de productielijn is, \(B\) de gerealiseerde breedte van het eindproduct en \(S\) de lijnsnelheid. Door de gezamenlijke verdeling van deze variabelen te analyseren, kunnen we zien welke combinaties leiden tot een kwaliteitsproduct.
Beeldherkenning:
\[P(L,\, P_1, P_2, \ldots, P_n)\]
waarbij \(L\) het label is (bv. “kat” of “hond”) en \(P_i\) de pixelwaarde op positie \(i\). Een typische afbeelding heeft duizenden pixels — de kansverdeling leeft dus in een ruimte met duizenden dimensies. Machine learning probeert patronen te vinden in deze gigantische ruimte.
3.2 Associatie
In 1929 ontdekte Edwin Hubble een interessant verband tussen de afstand van naburige melkwegstelsels en de snelheid waarmee ze van ons weg bewegen.
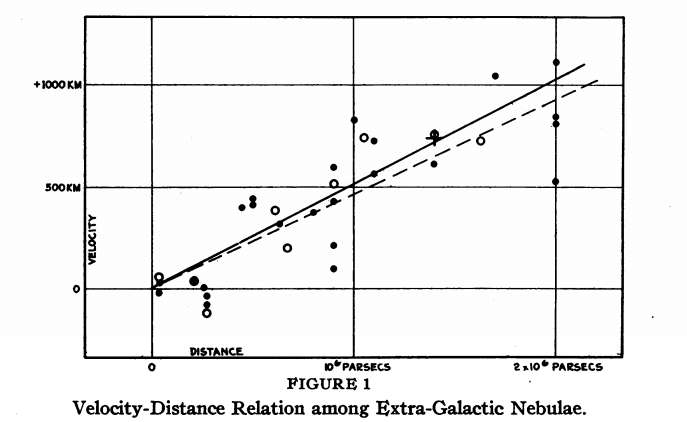
Als we zien dat verschillende variabelen samen bewegen zeggen we dat er een associatie is tussen de variabelen.
Associatie houdt in dat je de kolommen van de dataset niet onafhankelijk van elkaar kan onderzoeken. Eigenlijk willen we uitdrukken dat de gecombineerde dataset \(X, Y\) informatie bevat die we niet kunnen achterhalen door de partiële datasets met enkel \(X\) en \(Y\) apart te bestuderen. Om dit concept wiskundige te onderbouwen moeten we een nieuwe notie invoeren:
3.3 Marginale kansverdeling
Uit elke hoog-dimensionale dataset kan je een laag-dimensionale maken door variabelen (features) te schrappen. Als je de data bekijkt als een tabel komt het erop neer dat je bepaalde kolommen wegfiltert.
Het equivalent concept voor de kansverdeling is de marginale kansverdeling:
\[P(X) = \int_{y} P(X,\, Y = y)\,dy\]
Dus \(P(X)\) representeert de dataset die je bekomt door de kolom (of kolommen) die met \(Y\) overeenkomen te schrappen uit de data.
Onafhankelijkheid
Het begrip marginale verdeling brengt ons bij het cruciale concept van onafhankelijkheid. Twee variabelen \(X\) en \(Y\) zijn onafhankelijk als:
\[P(X,\, Y) = P(X) \cdot P(Y)\]
Met andere woorden: de kennis van \(X\) geeft geen extra informatie over \(Y\).
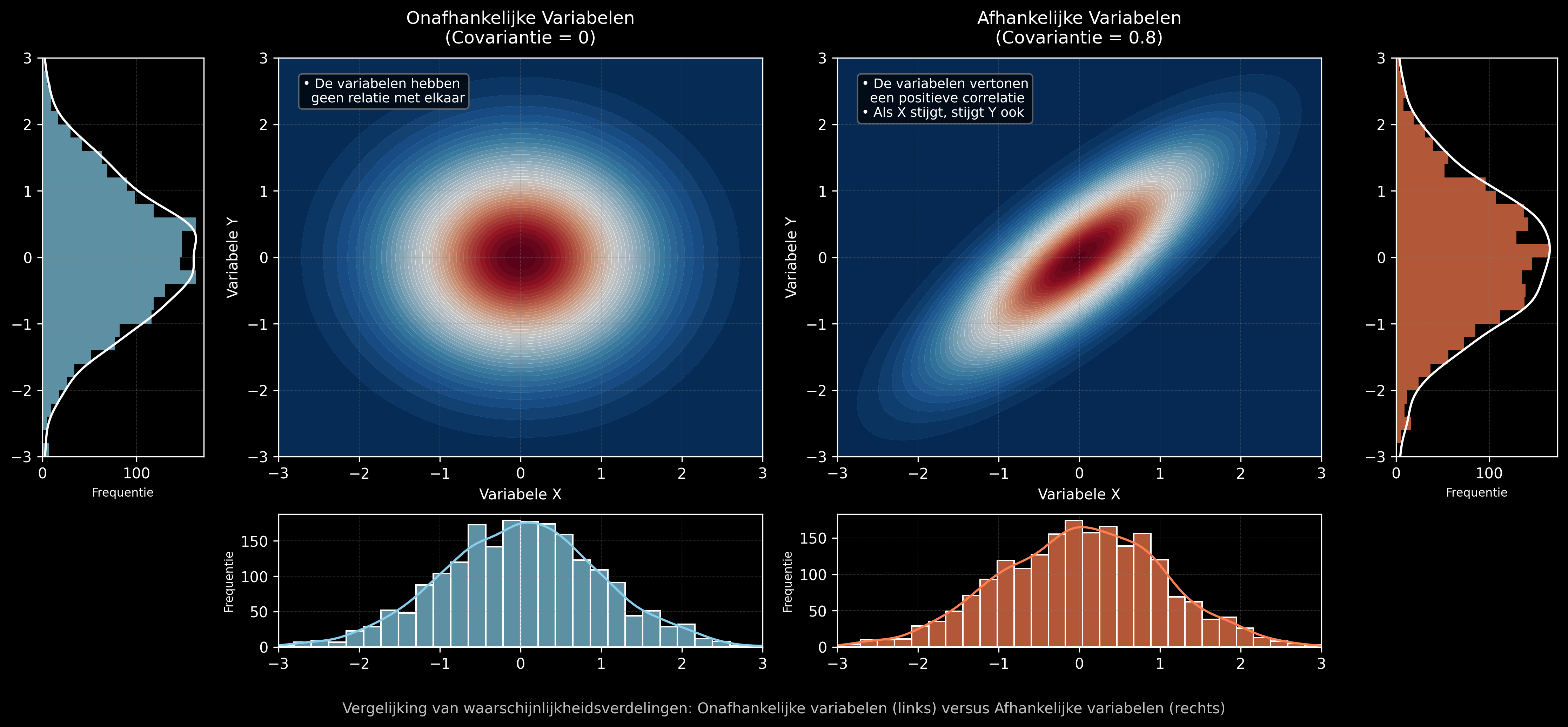
In de praktijk zijn dingen bijna nooit onafhankelijk: productiesnelheid beïnvloedt kwaliteit, temperatuur beïnvloedt slijtage, omzetcijfers hangen samen met marktomstandigheden, enzovoort.
3.4 Voorwaardelijke kansverdeling
De voorwaardelijke kansverdeling \(P(Y \mid X)\) beschrijft de verdeling van \(Y\) gegeven dat \(X\) een bepaalde waarde aanneemt:
\[P(Y \mid X) = \frac{P(X,\, Y)}{P(X)}\]
In termen van data: dit is equivalent aan het filteren van de dataset op rijen waar \(X \approx x\).
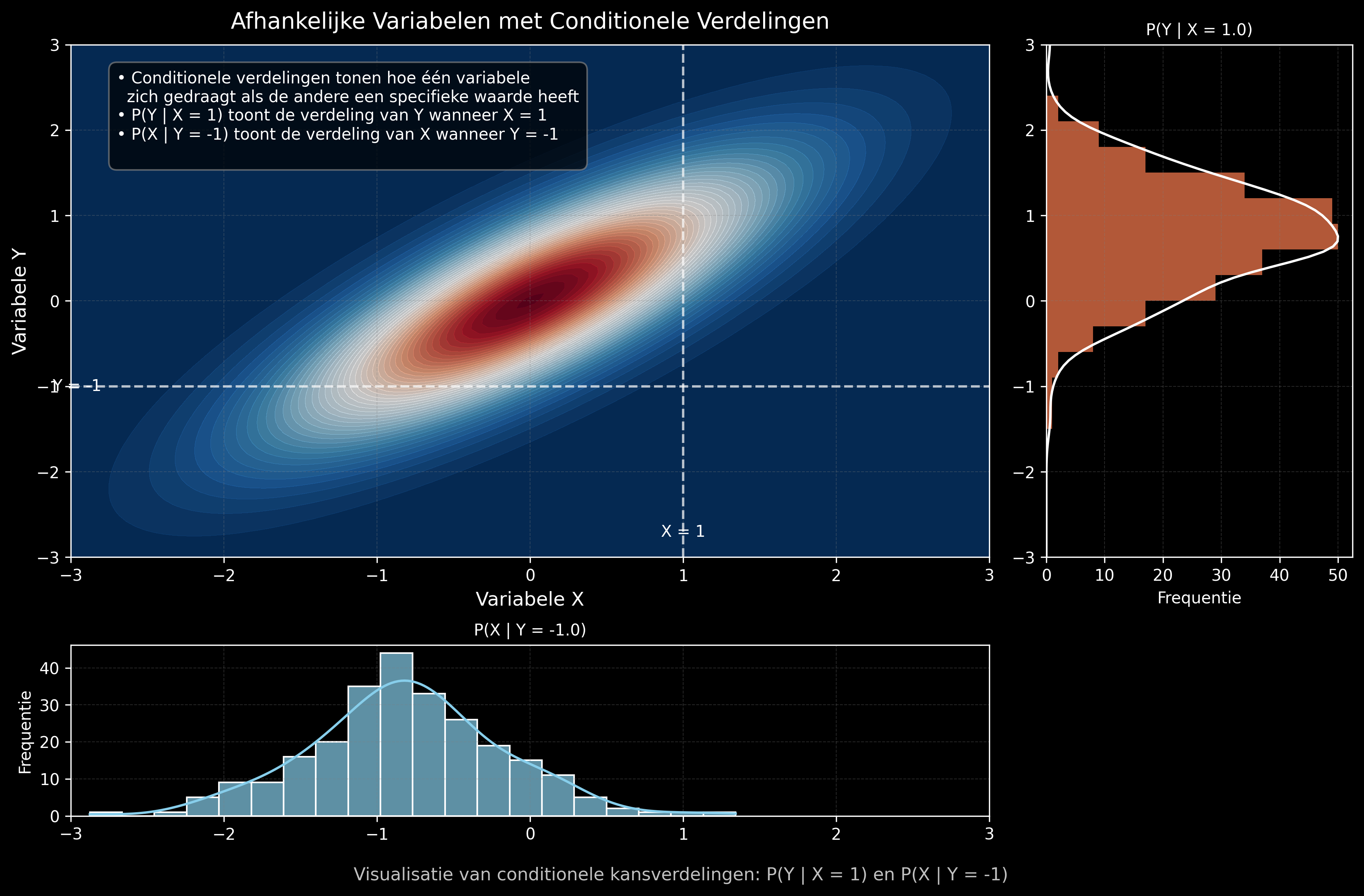
Onafhankelijkheid revisited
De voorwaardelijke verdeling geeft ons een andere manier om over onafhankelijkheid na te denken. Vermits
\[ P(X, Y) = P(X) \cdot P(Y \mid X) \]
altijd het geval is (bij definitie); en
\[ P(X, Y) = P(X) \cdot P(Y) \]
het geval is exact wanneer \(X\) en \(Y\) onafhankelijk zijn, is onafhankelijkheid ook equivalent met
\[ P(Y \mid X) = P(Y) \]
Met andere woorden: voorkennis van de waarde van \(X\) geeft geen extra informatie over \(Y\).
Intuïtie
We komen terug op de gewichten van mannen en vrouwen: als “geslacht” en “gewicht” onafhankelijke variabelen zouden zijn, dan zou \(P(M \mid G = \text{man}) = P(M) = P(M \mid G = \text{vrouw})\). In het bijzonder zouden mannen en vrouwen gemiddeld even zwaar zijn! Dat dit niet het geval is, impliceert dus dat de variabelen niet onafhankelijk zijn.
Oefening: productiekwaliteit en productielijnen
Beschouw de volgende data van 500 producten vervaardigd op twee productielijnen:
| Goedgekeurd | Afgewaardeerd | Afgekeurd | Totaal | |
|---|---|---|---|---|
| Lijn 1 | 200 | 50 | 20 | 270 |
| Lijn 2 | 150 | 40 | 40 | 230 |
| Totaal | 350 | 90 | 60 | 500 |
- Bereken \(P(L = \text{lijn 2},\; K = \text{Goedgekeurd})\)
- Bereken de marginale verdeling \(P(K)\) over kwaliteitsklassen
- Bereken de voorwaardelijke verdeling \(P(K \mid L = \text{lijn 1})\)
- Zijn productielijn en kwaliteit onafhankelijk? Motiveer uw antwoord.
Antwoorden
\(P(L = \text{lijn 2},\, K = \text{Goedgekeurd}) = \dfrac{150}{500} = 0{,}30\)
\(P(K = \text{Goedgekeurd}) = \dfrac{350}{500} = 0{,}70\); \(\quad P(K = \text{Afgewaardeerd}) = \dfrac{90}{500} = 0{,}18\); \(\quad P(K = \text{Afgekeurd}) = \dfrac{60}{500} = 0{,}12\)
\(P(K = \text{Goedgekeurd} \mid L = \text{lijn 1}) = \dfrac{200}{270} \approx 0{,}74\); \(\quad P(K = \text{Afgekeurd} \mid L = \text{lijn 1}) = \dfrac{20}{270} \approx 0{,}07\)
Neen — lijn en kwaliteit zijn niet onafhankelijk. Lijn 1 heeft een afkeuringsgraad van \(\approx 7\%\), terwijl lijn 2 \(\approx 17\%\) scoort. Wiskundig: \(P(L = \text{lijn 1},\, K = \text{Goedgekeurd}) = 0{,}40 \neq P(L = \text{lijn 1}) \cdot P(K = \text{Goedgekeurd}) = \tfrac{270}{500} \cdot \tfrac{350}{500} \approx 0{,}378\).
3.5 Voorwaardelijke verwachtingswaarde
De voorwaardelijke verwachtingswaarde \(\mathbf{E}[Y \mid X = x]\) is het gemiddelde van de voorwaardelijke verdeling \(P(Y \mid X = x)\):
\[\mathbf{E}[Y \mid X = x] = \int_{y} y \cdot P(Y = y \mid X = x)\,dy\]
Dit is een functie die enkel afhangt van \(x\), we noemen dit ook de regressielijn — het is één van de meest fundamentele concept uit de machine learning.
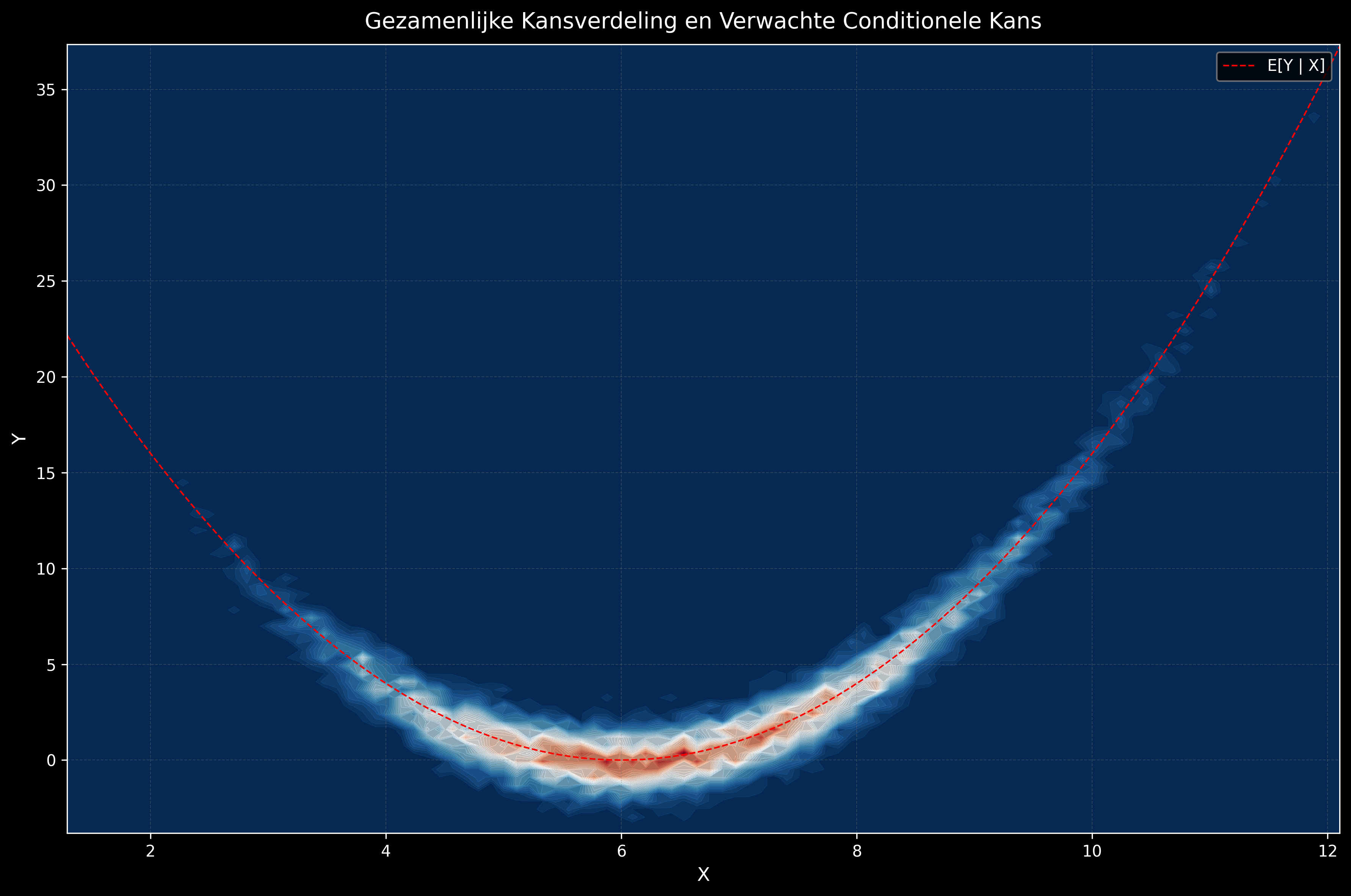
Te onthouden
Veel machine learning-methoden — van eenvoudige lineaire regressie tot complexe neurale netwerken — zijn in essentie allemaal schattingen van de voorwaardelijke verwachtingswaarden (en soms van de volledige voorwaardelijke verdeling \(P(Y \mid X)\)). Dit is het statistische fundament van alle supervised learning. We komen hierop terug in lecture 2.
4 Interventie
Tot dusver spraken we over het beschrijven en voorspellen van associaties in data. Om processen aan te sturen willen we meestal ook ingrijpen: introduceren van andere leveranciers, instellen van setpoints voor procesparameters, aanbrengen van nieuwe werkwijzen, enzoverder.
De zogenaamde ladder van causaliteit van wiskundige Judea Pearl beschrijft drie niveaus van redenering over data:
- Associatie (zien): “Wat gaat er samen?” — \(P(Y \mid X)\)
- Interventie (doen): “Wat als ik dit verander?” — \(P(Y \mid do(X))\)
- Counterfactueel (verbeelden): “Wat als het anders was gegaan?”
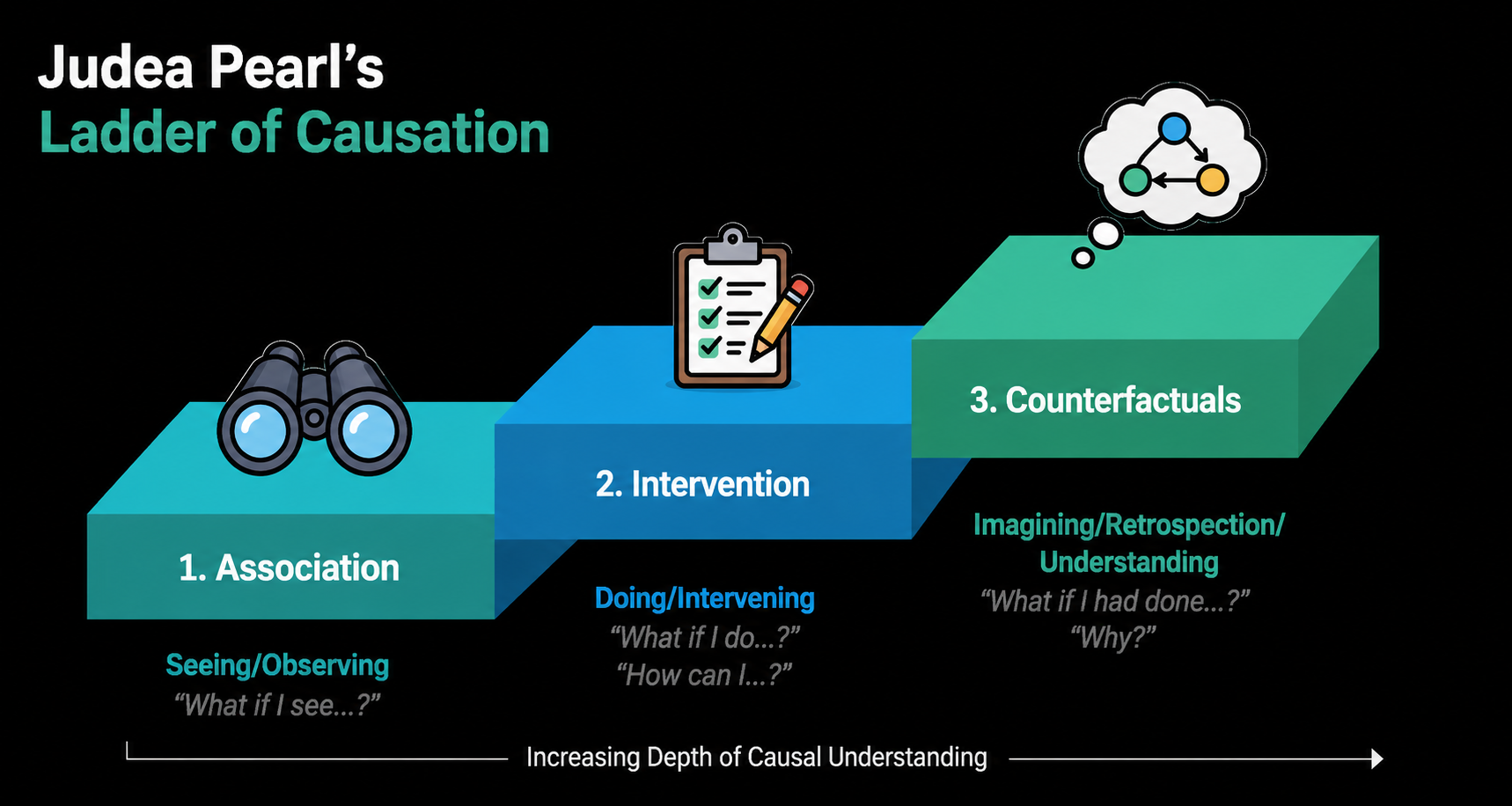
De technieken uit het vorige deel leren ons associaties detecteren. Maar wanneer we willen ingrijpen, volstaan louter associaties niet meer.
4.1 Inleidend voorbeeld: een fabriek en een carcinogeen
Een fabriek verbruikt “Verbinding X” in haar productieproces en stoot tegelijkertijd “Carcinogene stof Y” uit. Op basis van historische observaties stellen we een duidelijke associatie vast: meer Verbinding X gaat gepaard met meer uitstoot van Y.
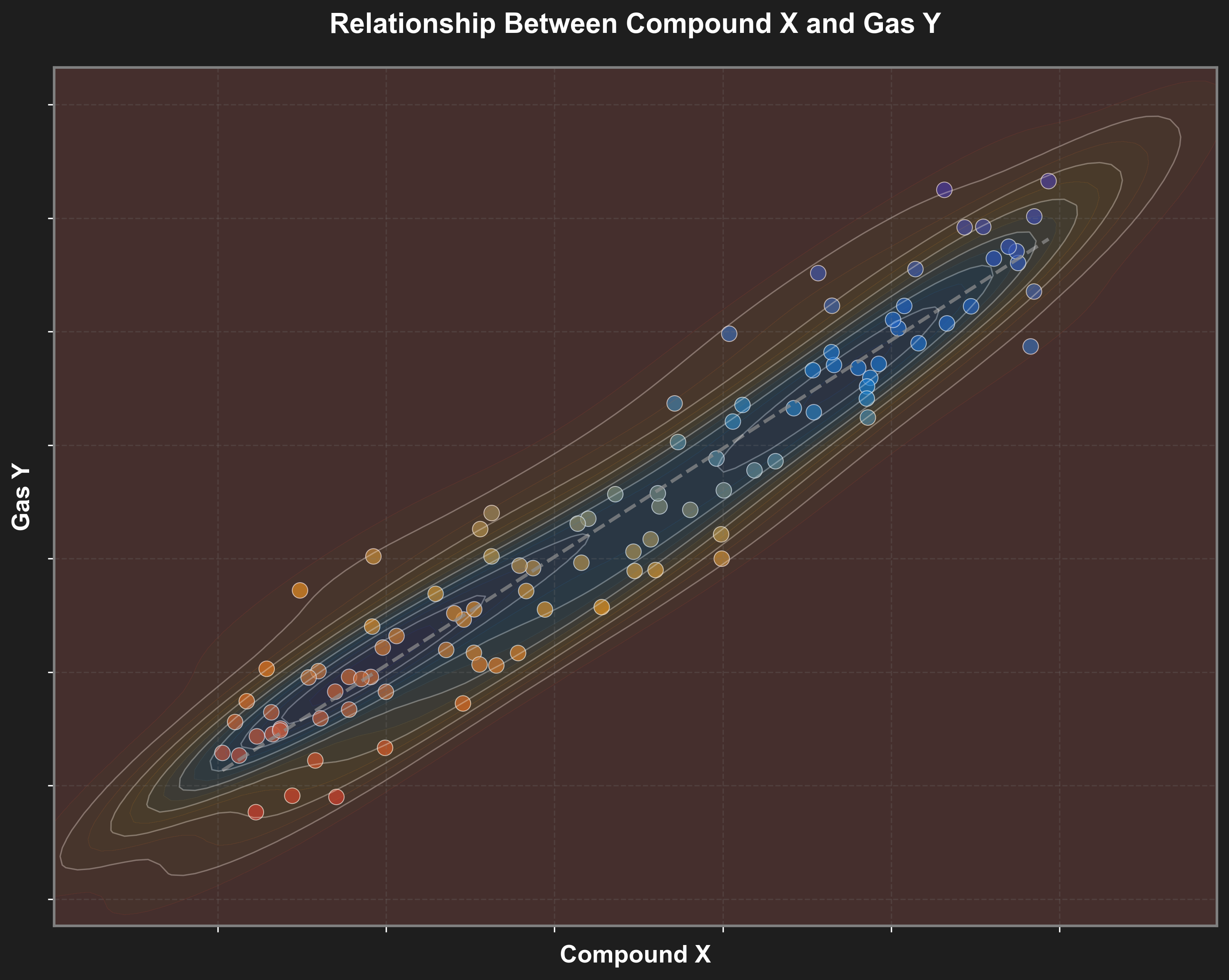
De logische interventie lijkt: verlaag het verbruik van Verbinding X. Stel dat we deze interventie in werkelijkheid uitvoeren, dan verwachten we een overeenkomstige daling van de uitstoot. We stellen ons dus voor dat we zoiets zullen bekomen:
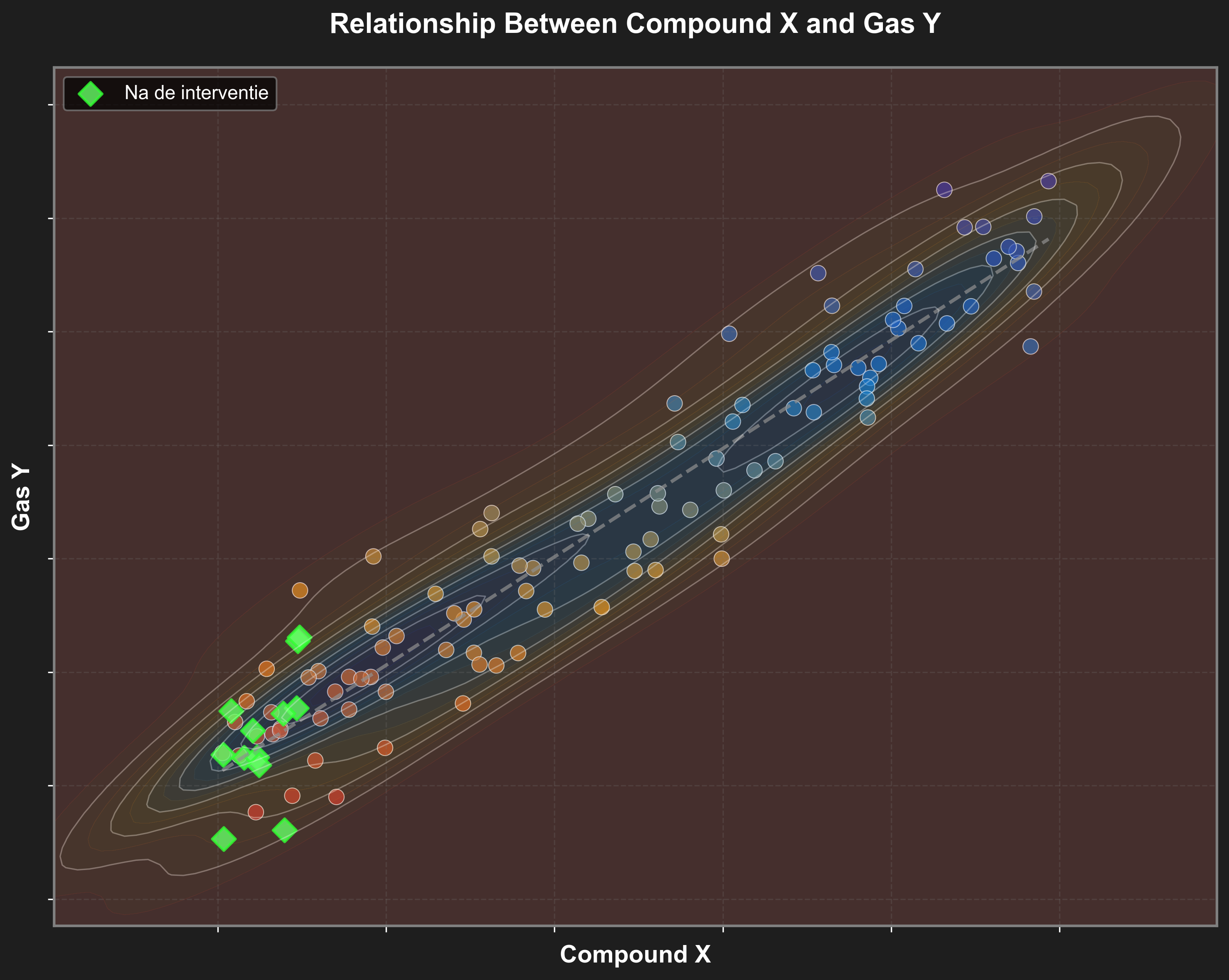
In de werkelijkheid kan het verkregen effect echter volledig anders uitvallen:
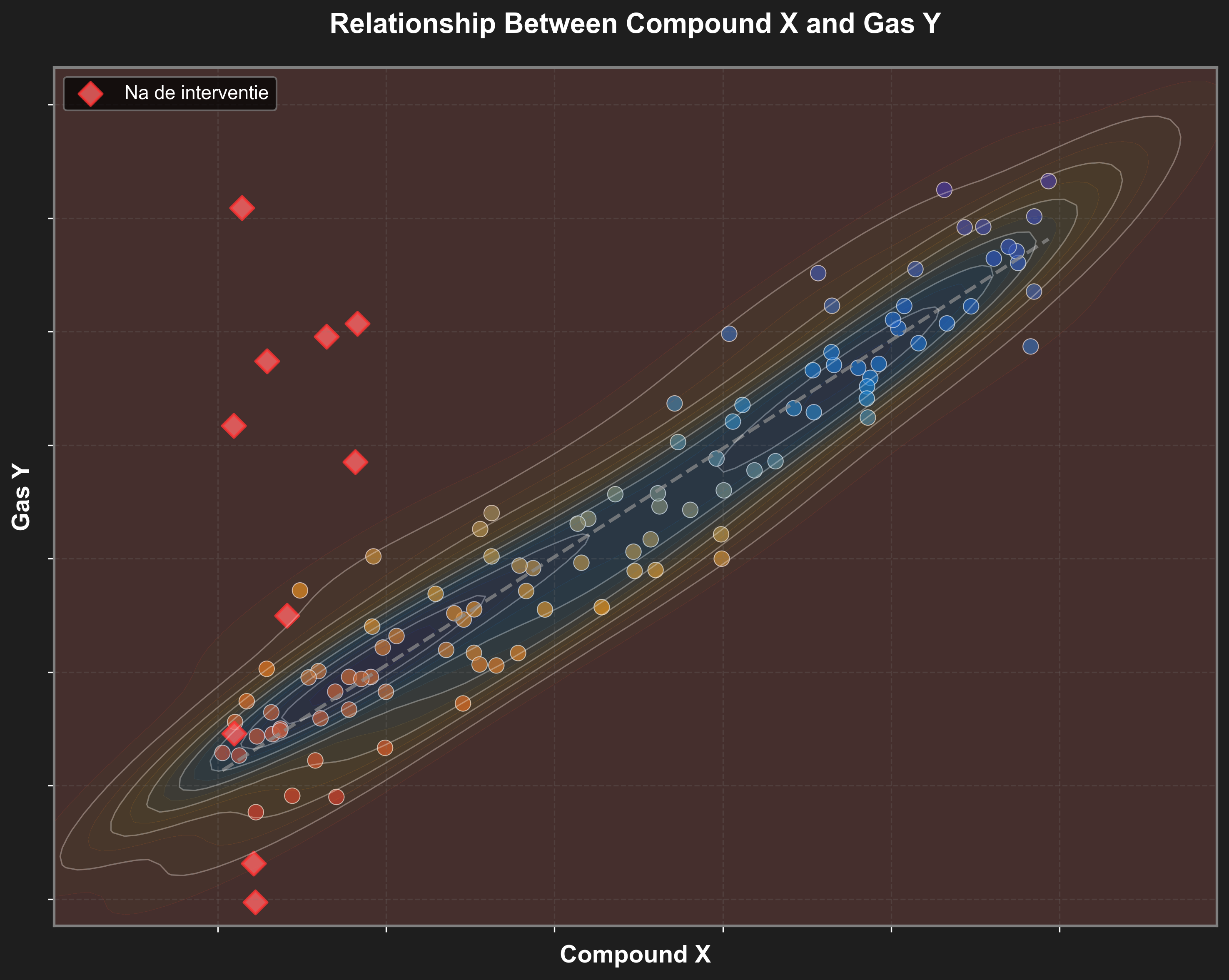
Beide situaties zijn in de praktijk absoluut mogelijk en allebei zijn compatibel met de data!
Wat loopt er verkeerd in de redenering? Denk hier zelf over na!
Illustratie: ijsverkoop en reddingsacties aan zee
Als je bovenstaande moeilijk te geloven vindt, hier is een ander voorbeeld.
Een kustgemeente houdt bij hoeveel ijscrèmes ze per dag verkoopt (\(X\)) en hoeveel reddingsacties de kustwacht uitvoert (\(Y\)). Er is een duidelijke positieve correlatie: op dagen met veel ijsverkoop zijn er ook meer reddingsacties.
Wat zou er gebeuren als de gemeente de ijsverkoop zou verbieden?
Het antwoord is: helemaal niets — tenminste wat betreft het aantal verdrinkingen. Zowel de ijsverkoop als het aantal verdrinkingen worden aangedreven door een derde factor: het warme weer dat mensen naar het strand trekt. IJsverkoop is een geassocieerd met reddingsacties, maar geen oorzaak.

Te onthouden
Zelfs het meest geavanceerde machine learning model, zoals een neuraal netwerk met 1000 lagen, kan dit onderscheid niet maken: het kan nooit meer doen dan de gezamelijke kansverdeling \(P(X, Y)\) modelleren — en die is identiek, of X nu de oorzaak is van Y, Y de oorzaak van X, or beide een gevolg zijn van een derde variabele Z.
4.2 Tweede voorbeeld: de paradox van Simpson
De kwade gevolgen van correlatie als causaal te aanzien kunnen nog veel verder gaan. Een berucht gevaar is Simpson’s paradox: een verband dat gevonden wordt uit observationele data kan zelfs het omgekeerde teken hebben van het correcte causale verband.
Bekijk volgend voorbeeld waar meer van een medicijn toedienen de patient een slechtere uitkomst lijkt te bieden:
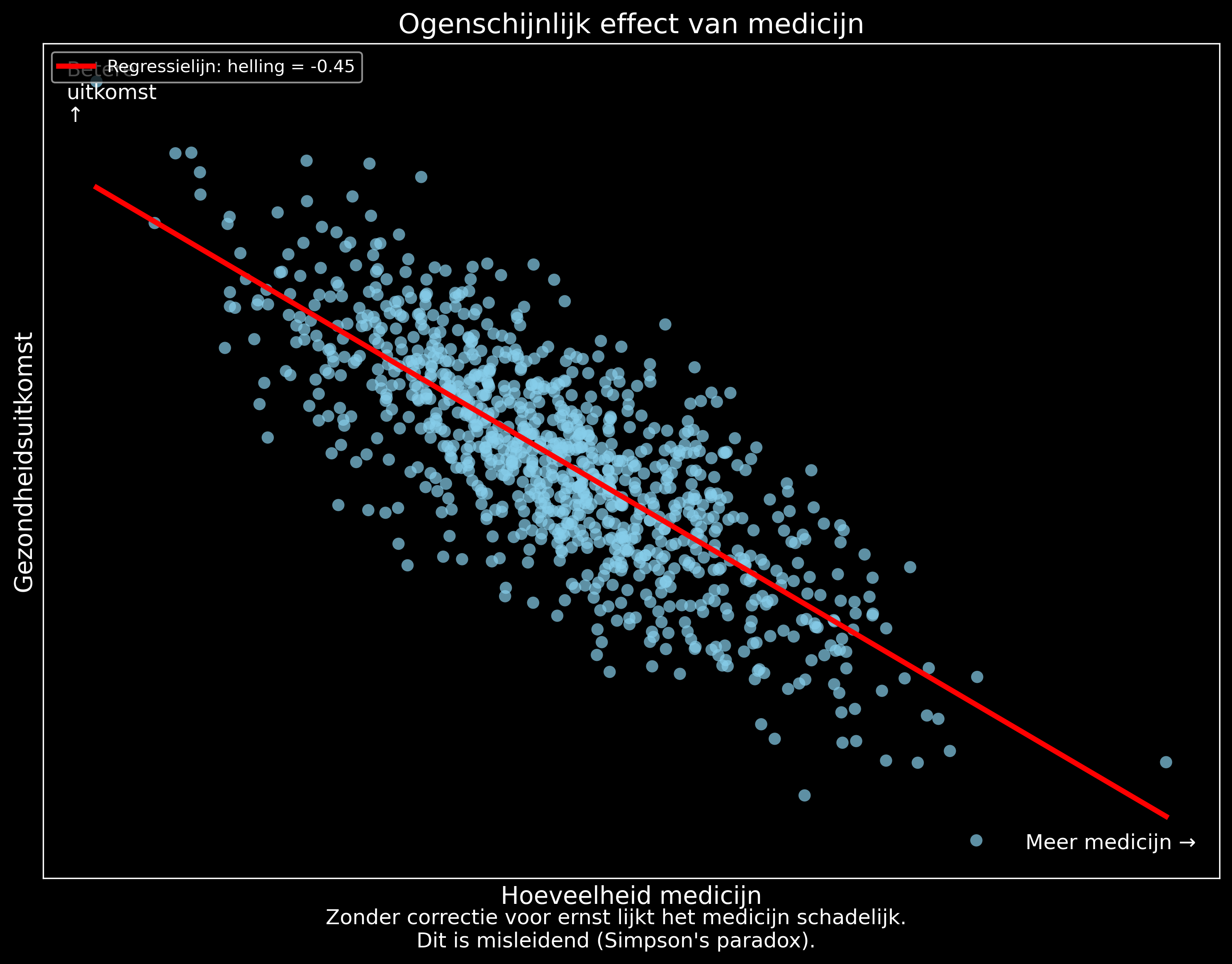
De oorzaak van Simpson’s paradox is een confounder: een variabele die zowel de behandeling als de uitkomst beïnvloedt. In het medicijnvoorbeeld is dit de ernst van de aandoening. Het naïeve beeld van oorzaak en gevolg — dat de confounder negeert — leidt tot een verkeerde conclusie:
graph LR
A["Hoeveelheid medicijn (A)"] --> B["Gezondheidsuitkomst (B)"]
Als we de data opsplitsen in groepen van patiënten met ongeveer dezelfde ernst van de aandoening zien we dat meer medicijn een gunstig effect heeft.
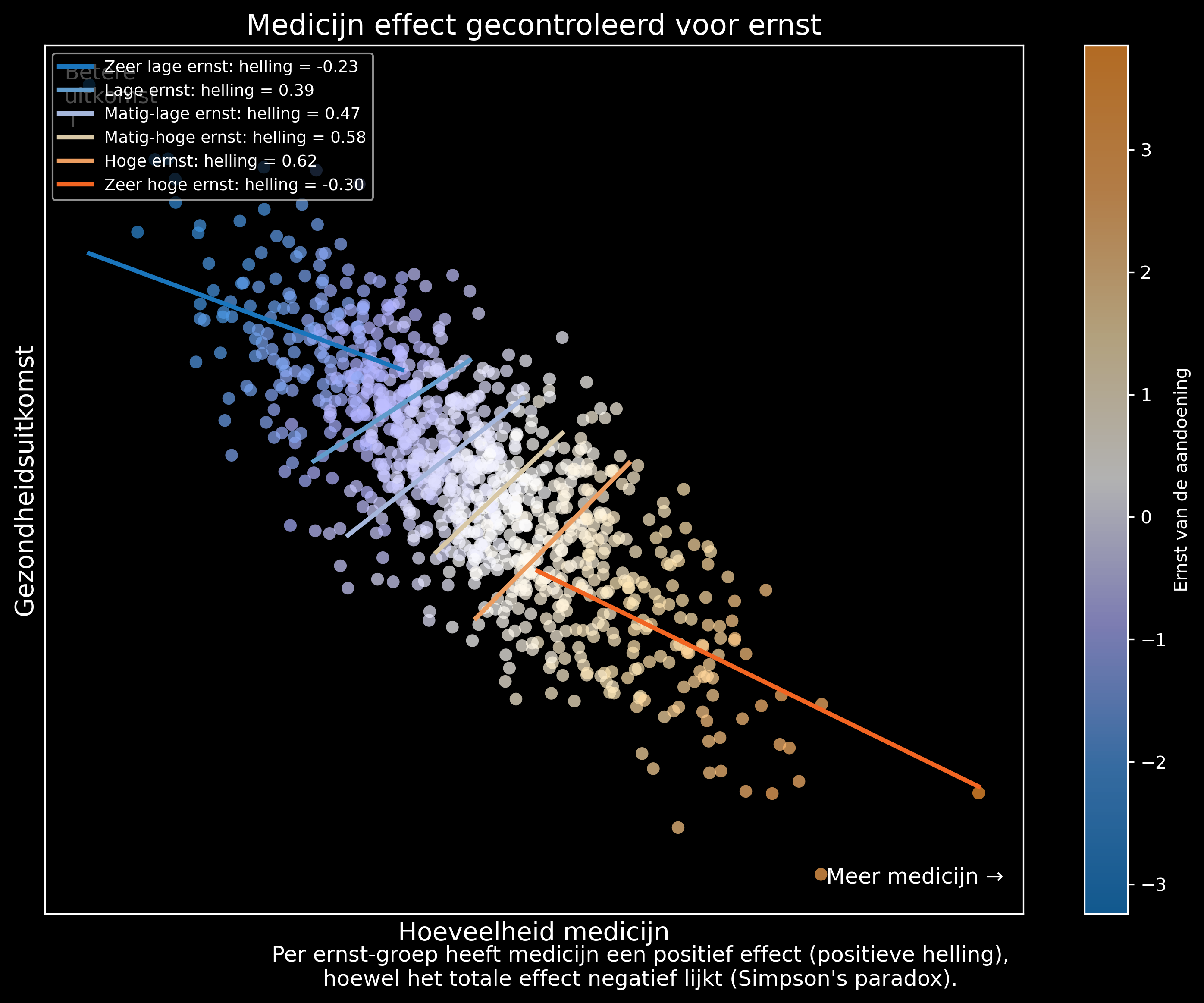
Een correctere manier om over de oorzaak en gevolg na te denken is daarom gegeven door:
graph LR
C["Ernst van de aandoening (C)"] --> A["Hoeveelheid medicijn (A)"]
C --> B["Gezondheidsuitkomst (B)"]
A --> B
Patiënten met een ernstigere aandoening krijgen meer medicijn én hebben sowieso een slechtere gezondheidsuitkomst. Wie de confounder \(C\) negeert, ziet een schijnbaar negatief verband tussen medicijn en gezondheid — terwijl het medicijn in elke subgroep wél helpt.
Zonder extra aannames is causale inferentie onmogelijk
Uit observationele data alleen kunnen we het effect van een interventie in het algemeen niet bepalen. We hebben altijd bijkomende causale aannames nodig — die typisch afkomstig zijn uit domeinkennis of theoretische modellen.
4.3 Het PINO-principe
Correlatie is geen causatie. Geheugensteuntje: onthou het PINO-principe.
PINO: Prediction Is Not Optimization
Met andere woorden: het is niet omdat je er (correct) in slaagt om te observaties te voorspellen dat je de juiste acties zal voorstellen om een gewenst effect te bekomen.
In de literatuur staat dit ook bekend als
De “Cum hoc ergo propter hoc”-fallacy
Het cruciale onderscheid is:
- \(P(Y \mid X = x)\): de kansverdeling van \(Y\) gegeven dat we observeren dat \(X = x\). Dit gaat over associatie: als ik een observatie maak waar \(X \approx x\), dan kan ik iets zeggen over de \(Y\) die ik verwacht te observeren;
- \(P(Y \mid do(X = x))\): de kansverdeling van \(Y\) gegeven dat we interveniëren en de waarde van \(X\) forceren op \(x\).
In het algemeen geldt: \(P(Y \mid X = x) \neq P(Y \mid do(X = x))\). Kansverdelingen vertellen ons wat samen voorkomt, maar niet waarom.
In bedrijfsperspectief
Stel dat data toont: “Producten van lijn 1 worden vaker afgekeurd dan producten van lijn 2.”
- Associatievraag: Wat is de kans op afkeur, gegeven dat een product toevallig op lijn 1 gemaakt werd? \(\to P(K = \text{afgekeurd} \mid L = \text{lijn 1})\)
- Interventievraag: Wat is de kans op afkeur als we beslissen om alle productie naar lijn 2 te verplaatsen? \(\to P(K = \text{afgekeurd} \mid do(L = \text{lijn 2}))\)
Het antwoord op de eerste vraag geeft geen garantie voor het antwoord op de tweede. Lijn 1 kan meer afkeur vertonen omdat er systematisch moeilijker producten op worden gemaakt, of zelfs omdat de detectiegrenzen voor afkeur scherper staan ingesteld — niet omdat de lijn zelf slechter is.
Om te begrijpen wat \(P(Y \mid do(X = x))\) is, komen we formeel terug op de diagrammen van hierboven:
4.4 Causale diagrammen
Een manier om het onderscheid tussen associatie en interventie te formaliseren gebruikt causale diagrammen.
In causaal diagram zijn er:
- knopen (nodes of vertices) de variabelen in ons systeem
- pijlen (edges) de veronderstelde causale relaties tussen variabelen
- mag geen enkele variabele zijn eigen oorzaak zijn, zelfs niet indirect (acyclisch)
Een causaal diagram is een voorbeeld van een DAG (Directed Acyclic Graph).
Een causaal diagram is in feite een bijkomende aanname over het fysisch proces dat onze data genereert.
Oefening
Dit eenvoudige causaal diagram beschrijft de sterkte van staal dat gemaakt wordt door schroot te hersmelten. De sterkte hangt af van chemische elementen Cu, Ni en Cr, die afkomstig zijn uit de ingezette schrootmix.
graph TD
S["schroot"] --> Ni
S --> Cu
S --> Cr
Ni --> ST["Sterkte"]
Cu --> ST
Cr --> ST
Stel dat we uit observationele data weten dat het verhogen van de waarde van koper met 100 ppm leidt tot een grotere sterkte van 10 MPa. Leg in woorden uit waarom extra koper legeren misschien zal werken, en misschien niet zal werken!
Antwoord
Als we staal observeren met hoog koper, zal dit vermoedelijk ook een andere schrootmix hebben meegekregen. Daardoor is het plausibel dat ook de andere chemische elementen andere typische waarden hebben. Bijvoorbeeld zal schroot met hoog koper, typisch ook hogere nikkel hebben.
Met andere woorden, er is “achterdeur”: een tweede, niet-causale manier waarop de gemeten koper invloed heeft op sterkte: \(Cu \to \text{schroot} \to Ni \to \text{Sterkte}\).
4.5 Interventie formaliseren
Met de hulp van het causaal diagram kunnen we formeel omschrijven wat het uitvoeren van een interventie is:
Een interventie forceert een variabele naar een bepaalde waarde — dit verbreekt de natuurlijke causale relaties die normaal die variabele bepalen. In het diagram vertaalt dit zich als: verwijder alle inkomende pijlen naar de geïntervenieerde variabele.
Cruciaal inzicht: een inverventie modificeert het causaal diagram, en \(P(Y \mid do(X))\) lees je af in een gemodificeerd diagram.
Voorbeeld: koper legeren in staal
In het schrootmodel wordt de koperwaarde \(Cu\) normaal bepaald door de schrootmix: \(\text{schroot} \to Cu\). Stel dat we actief koper bijlegeren — d.w.z. we interveniëren: \(do(Cu = x)\).
De interventie forceert \(Cu\) op een vaste waarde en verbreekt de band met schroot. De inkomende pijl \(\text{schroot} \to Cu\) verdwijnt uit het diagram:
graph TD
S["schroot"] --> Ni
S --> Cr
Cu:::intervened --> ST["Sterkte"]
Ni --> ST
Cr --> ST
classDef intervened fill:#555,stroke:#fff,color:#fff
De “achterdeur” via schroot is nu gesloten: \(Cu\) hangt niet meer samen met de schrootmix en dus ook niet meer indirect met \(Ni\) en \(Cr\). Het gemeten effect van koper op sterkte weerspiegelt nu het zuivere causale effect \(P(\text{Sterkte} \mid do(Cu = x))\), vrij van confounding.
4.6 Belang van randomisatie
De gouden standaard voor het meten van causale effecten is de Randomized Controlled Trial (RCT):
- Deelnemers of eenheden worden willekeurig toegewezen aan een interventie- of controlegroep
- Willekeurige toewijzing elimineert alle systematische verschillen: zelfs die variabelen waar we helemaal nog niet aan gedacht hebben
- In een RCT geldt: \(P(Y \mid do(X = x)) = P(Y \mid X = x)\)
Het idee: door eenheden volledig willekeurig toe te wijzen kan je de pijlen doorknippen die de gegeven variabele beïnvloeden. In die situatie weet je dan dat je toewijzing ook een oorzakelijk verband heeft met het bekomen resultaat.
In de industrie en e-commerce staat dit bekend als A/B testen: je verdeelt gebruikers, batches of periodes willekeurig over twee condities en meet het effect.
Voorbeeld uit e-commerce
Een webshop wil weten of een nieuwe productpagina de conversie verhoogt. Ze tonen de nieuwe pagina willekeurig aan 50% van de bezoekers en de oude aan de overige 50%. Na een week vergelijken ze de conversiepercentages. Het gemeten verschil is een causale schatting van het effect van de nieuwe pagina — niet enkel een associatie.

Causaal diagram van een klinische studie
Beschouw een klinische studie naar het effect van een behandeling \(T\) op een gezondheidsuitkomst \(Y\). In de praktijk zijn er confounders — variabelen zoals leeftijd, ernst van de aandoening of levensstijl — die zowel de kans op behandeling als de uitkomst beïnvloeden.
Zonder randomisatie (observationele studie) bepalen confounders mede wie de behandeling krijgt en wie geneest. Er bestaan achterdeurpaden van \(T\) naar \(Y\) via de confounders:
graph LR
C["Confounders\n(leeftijd, ernst, …)"] --> T["Behandeling (T)"]
C --> Y["Uitkomst (Y)"]
T --> Y
Het pad \(T \leftarrow C \rightarrow Y\) is een achterdeurpad: \(C\) is een gemeenschappelijke oorzaak van zowel \(T\) als \(Y\). De geobserveerde associatie \(P(Y \mid T)\) mengt daardoor het causale effect van \(T\) met de invloed van de confounders.
Met randomisatie (RCT) wordt de toewijzing van de behandeling bepaald door een willekeurig mechanisme \(R\) — volledig onafhankelijk van elke confounder. Dit is precies equivalent aan het verwijderen van alle inkomende pijlen naar \(T\):
graph LR
R(["Randomisatie (R)"]) --> T["Behandeling (T)"]
C["Confounders\n(leeftijd, ernst, …)"] --> Y["Uitkomst (Y)"]
T --> Y
Er bestaat nu geen pad meer van \(C\) naar \(T\): alle achterdeurpaden zijn afgesneden. Daarmee geldt in een RCT:
\[P(Y \mid do(T = t)) = P(Y \mid T = t)\]
Het gemeten verschil in \(Y\) tussen de behandel- en controlegroep is een zuivere schatting van het causale effect — vrij van confounding door welke variabele dan ook, ook door variabelen die we nooit hebben gemeten.
4.7 Do-calculus als antwoord
Randomisatie is lang niet altijd mogelijk:
- Ethische bezwaren: men kan mensen niet willekeurig laten roken om het effect op gezondheid te meten
- Praktische beperkingen: het klimaat valt niet willekeurig aan te passen
- Financiële kosten: een productieproces weken lang “willekeurig” runnen is duur en operationeel riskant
Soms hebben we geen andere keuze dan te werken met observationele data — data die de natuur, of ons productieproces, voor ons heeft gegenereerd zonder dat wij actief hebben ingegrepen.
Do-calculus is een techniek bedacht door Judea Pearl die toelaat om interventionele effecten, zoals \(P(Y \mid do(X))\) uit te drukken als functie van normale, geobserveerde associaties. Niet elk interventioneel effect kan op deze manier geïdentificeerd worden maar als het mogelijk is, kan do-calculus het.
4.8 Alternatieve technieken voor causale inferentie
Naast Pearls do-calculus zijn er andere methoden om causale inferentie te doen, de populariteit van bepaalde methoden kan soms samengaan het het vakgebied. Belangrijk voor ons is vooral dat elke methode afhangt van causale veronderstellingen over de data.
| Methode | Kernidee |
|---|---|
| Matching & propensity scores | Vergelijk behandelde en onbehandelde eenheden die zo gelijkaardig mogelijk zijn op alle gemeten confounders. |
| Instrumentele variabelen | Gebruik een variabele die de behandeling beïnvloedt maar de uitkomst niet (behalve via de behandeling). |
| Difference-in-differences | Vergelijk de evolutie over tijd tussen behandelde en niet-behandelde groepen. |
| Regressie-discontinuïteit | Exploiteer een willekeurige drempelwaarde waarbij de behandeling abrupt verandert. |
| Structurele vergelijkingsmodellen | Schat het volledige causale systeem via een set van simultane vergelijkingen. |
4.9 Praktijkvoorbeeld
Koelt warm staal sneller af dan koud staal?
Een staalpan koelt af gedurende een bepaalde periode. De temperatuur wordt gemeten vóór (\(M_1\)) en na (\(M_2\)) de afkoelperiode.
De vraag is: koelt warm staal sneller af dan koud staal? Intuïtief zou de regressielijn \(\mathbf{E}[M_2 \mid M_1 = m]\) dit moeten vertellen. Er is echter een subtiliteit: de temperatuur wordt gemeten met meetfout.
Een zinnig causaal model moet daarom zowel de werkelijke als de gemeten temperaturen vermelden:
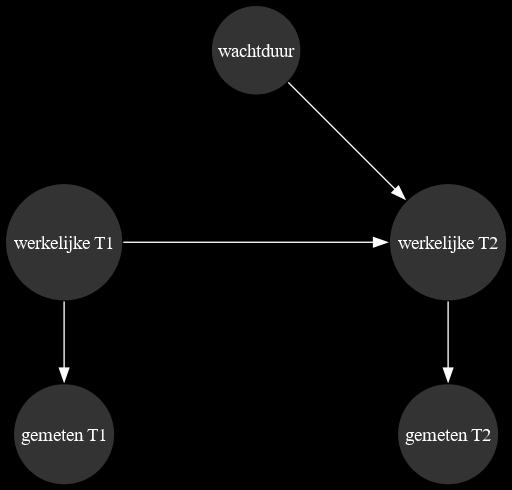
De werkelijke temperatuur is een zinnig theoretisch concept, maar kan zelf geen deel uitmaken van onze dataset.
\[\begin{align} M_1 &= T_1 + \varepsilon_1 \\ M_2 &= T_2 + \varepsilon_2 \\ T_2 &= \alpha\, T_1 + \beta\, W + \varepsilon_0 \end{align}\]
waarbij \(T_i\) de werkelijke temperatuur is, \(W\) de wachttijd en \(\alpha\) de afkoelcoëfficiënt die we willen schatten. We kunnen nu een ad-hoc studie doen de parameter \(\alpha\) te schatten uit de data.
Met het correcte causale model geldt:
\[\alpha = \frac{\mathrm{Cov}(M_1,\, M_2)}{\mathrm{Var}(T_1)}\]
Stel dat we een klassieke lineaire regressie zouden toepassen (zonder correct causaal model) dan zouden we volgens de theorie de volgende coëfficiënt schatten:
\[\alpha' = \frac{\mathrm{Cov}(M_1,\, M_2)}{\mathrm{Var}(M_1)} = \frac{\mathrm{Cov}(M_1,\, M_2)}{\mathrm{Var}(T_1) + \mathrm{Var}(\varepsilon_1)} < \alpha\]
Met concrete waarden: zelfs als in werkelijkheid \(\alpha = 1\) (warm en koud staal koelen even snel af), concludeert het naïeve model mogelijk dat \(\alpha' \approx 0.94\) — alsof warm staal significant sneller afkoelt!
Dit effect staat bekend als regression dilution of attenuation bias: meetfouten in de onafhankelijke variabele leiden systematisch tot een onderschatting van de werkelijke relatie.
Te onthouden
Zelfs een ogenschijnlijk eenvoudige regressie-analyse kan leiden tot systematisch verkeerde conclusies indien men geen correct causaal model hanteert. Domeinkennis blijft belangrijk, zelfs in tijden van big data.
5 Studiewijzer
Na deze les bent u vertrouwd met de volgende begrippen:
Kanstheorie en statistiek: - Sampling en inference als complementaire processen (het verband begrijpen kanstheorie en data) - Weten wat een marginale kans is en deze kunnen berekenen in eenvoudige gevallen - Weten wat een voorwaardelijke kans is en deze kunnen berekenen in eenvoudige gevallen - Het begrip “onafhankelijkheid” van variabelen kennen - Kunnen nagaan of twee variabelen onafhankelijk zijn - Het begrip voorwaardelijke verwachtingswaarde intuïtief begrijpen
Causaliteit en interventie:
- Vertrouwd zijn met de cum hoc ergo propter hoc fallacy (het PINO-principe)
- Intuïtieve notie hebben van het begrip causaal diagram als representatie van causale structuren
- Eenvoudige causale redeneringen kunnen maken
- Weten dat randomized Controlled Trials en A/B-testen gouden standaard zijn om causale verbanden bloot te leggen
5.1 Literatuur
The Book of Why — Judea Pearl & Dana MacKenzie (2018)

Een toegankelijke inleiding tot de theorie van causaliteit, geschreven door de grondlegger van do-calculus. Bijzonder aanbevolen voor wie de intuïtie achter causale diagrammen en interventies beter wil begrijpen.